
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- GIT
- FinanceDataReader
- 영어한글폰트차이
- dataframe
- 수치형변수
- PANDAS
- Python
- Repositories
- 비밀지도
- 해커랭크
- github blog
- 데이터수집
- numpy
- Github
- Beautifulsoup
- 서울정보소통광장
- 120주요질문
- 숫자형
- googlefont
- 깃허브블로그
- 구글폰트
- 한국주식
- Requests
- seaborn
- 카카오채용코테'
- 깊은복사
- 프로그래머스
- hackerrank
- SettingWithCopyWarning
- 네이버금융
Archives
- Today
- Total
데린이 재영
네이버 금융 개별종목 수집하기 - Pandas/Requests/BeautifulSoup 본문
목표 설정
- 멋쟁이사자 AI 스쿨 8일차(220928) 학습 내용 정리하기
- Pandas, Requests, BeautifulSoup 라이브러리를 이용해서 네이버 금융 개별종식 데이터 수집하기
배운 내용 정리
1) 사용한 라이브러리 목록
# 테이블형태의 데이터 불러올 때 pd.read_html 사용
import pandas as pd
# pandas 짝꿍
import numpy as np
# HTTP 요청
import requests
# table 태그 찾을 때 사용
from bs4 import BeautifulSoup as bs
# time.sleep()으로 시간간격 두고 데이터 수집할 때 사용 - 서버 부담이 되기 때문
import time
# 실시간 시간정보 가져올 수 있음
from datetime import datetime
# 진행상태 알 수 있음
from tqdm import trange2) Requests
- pd.read_html 이 바로 사용안되는 경우에 사용 ▶ 테이블(table) 이 있어도 막힌 경우 사용이 안됨
- 셀레늄을 사용하는 경우가 있으나, 셀레늄은 브라우저 테스트용으로 만들어진 기능이기 때문에 Requests 사용하자!
- Network ▶ url 클릭 ▶ Doc ▶ url 클릭 ▶ Headers 보면 Requests url 찾을 수 있음
- Parameters
- method - GET, OPTIONS, HEAD, POST, PUT, PATCH, or DELETE
- Request Method
- 검사 ▶ Network ▶ 생성된 이름 클릭 ▶ Header 보면 Request Method 확인 가능 (get, post 등)
- request 로 데이터 수집해왔을 때, 200 OK 나오는지 확인 (200 OK == 수집이 잘 이루어졌다는 뜻)
- GET
- url로 전달하는 방식
- 필요한 데이터를 Query String에 담아 전송
- Query String : payload에 나와 있음
- 검사 ▶ Network ▶ 생성된 이름 클릭 ▶ Payload ▶ Query String Parameters 확인 가능
- POST
- 회원가입할 때, 물건이나 음식 주문할 때 메시지 입력하고 버튼 누를 때 등에 사용됨
- 전송할 데이터를 HTTP 메시지의 Body의 Form Data에 담아 전송
- 검사 ▶ Network ▶ 생성된 이름 클릭 ▶ Payload ▶ Form Data 확인 가능
3) BeautifulSoup
- 구조화 되어 있지 않은 것에서 원하는 정보를 찾아봐라! 하면 찾기 어려움 ▶ 구조화 필요시에 쓰임
- 데이터 수집용이 아닌, html, xml 문서를 파싱 ! 해석해서 얻고자하는 정보를 찾을 때 사용
- 데이터 형태
- 테이블 형태가 아니라면, beautiful soup으로 확인하기
- 테이블 형태라면, pd.read_html 바로 사용하기 (테이블 형태가 내장되어 있음)
- find_all
- 지정한 태그에 대한 모든 값을 가져옴
- 슬라이싱 기능 사용 가능 (예 : html.find_all("a")[:3])
- list 형태로 불러와짐
- select
- 지정한 태그에 대한 모든 값을 가져옴
- css selector 사용 가능
- 셀렉터의 장점
- Copy Selector 를 통해 원하는 태그를 가져올 수 있음
- 소스코드에 대한 경로값을 찾아올 수 있음
- 콕 ! 찝어서 원하는 태그를 지정할 수 있다
- 셀렉터로 경로 값 지정했을 때, 안뜨는 경우가 있음 ▶ 경로를 위로 하나씩 올라타고 하나씩 내려오면서 확인 필요
4) Pandas 기능
- 컬럼 추가 : df["컬럼명"] = item
- 컬럼 순서를 cols로 변경
cols = ['종목코드', '종목명', '날짜', '종가', '전일비', '시가', '고가', '저가', '거래량']
df = df[cols]- 중복데이터 제거 : drop_duplicates (행 요소들 끼리 data를 비교하여 같은 값이 있으면 행에서 하나를 삭제)
- 기술통계 : describe()
- 파일 저장하고 읽어오기
- 저장 : df.to_csv(file_name, index=False, encoding="cp949")
- 읽기 : pd.read_csv(file_name, encoding="cp949")
네이버 금융 '유한양행' 일별시세 정보 가져오기

# 필요한 라이브러리 로드
from bs4 import BeautifulSoup as bs
import pandas as pd
import numpy as np
import requests
import time
# 유한양행 종목코드 : 000100
page_no = 1
# 입력한 페이지에 대한 일별시세 정보 가져오기
def get_one_page(page_no):
# 유한양행의 일별시세, 페이지별 주소
url = f"https://finance.naver.com/item/sise_day.naver?code=000100&page={page_no}"
# requests로 HTTP 요청, headers로 봇이 아님을 알려주기
response = requests.get(url, headers={"user-agent": "Mozilla/5.0"})
# pandas로 데이터 수집하기
table = pd.read_html(response.text)
temp = table[0]
# 결측치 있는 row 제거하고 df로 지정
df = temp.dropna()
return df
>>> get_one_page(5)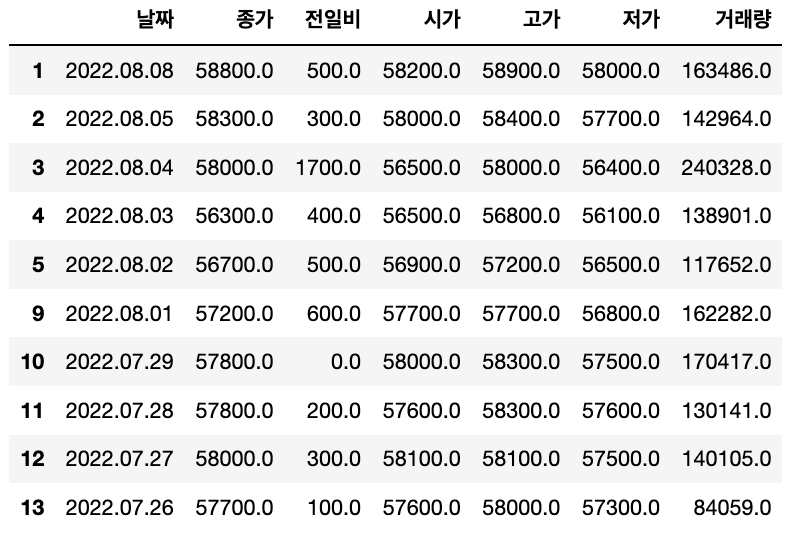
# 종목 코드, 종목 이름을 입력하면 개별 종목 일별시세 수집하는 함수
def get_all_page(item_code, item_name):
# 페이지 시작
page_no = 1
# 데이터를 합칠 리스트 만들기
all_page_list = []
# 반복문 종료시점을 위해 변수 생성하기
new_date = None
while True:
# 한 페이지의 일별 시세 수집
df_daily = get_one_page(page_no)
# 불러온 데이터에서 마지막 날짜 가져오기
end_date = df_daily.iloc[-1]["날짜"]
# 마지막 날짜가 바뀌지 않으면 stop
if end_date == new_date:
break
# new date 업데이트, df 추가, 페이지 수 += 1
new_date = end_date
all_page_list.append(df_daily)
page_no += 1
# 서버 과부하 방지를 위해 시간 텀을 두고 데이터 수집
time.sleep(0.01)
# 데이터 컬럼 추가
df_total = pd.concat(all_page_list)
df_total["종목코드"] = item_code
df_total["종목명"] = item_name
# 데이터 컬럼 순서 정리
cols = ['종목코드', '종목명', '날짜', '종가', '전일비', '시가', '고가', '저가', '거래량']
df_total = df_total[cols]
# 데이터 중복값 제거
df_total.drop_duplicates()
# 파일 저장 과정
date = df_total.iloc[0]["날짜"]
file_name = f"{item_name}_{item_code}_{date}.csv"
df_total.to_csv(file_name, index=False, encoding="cp949")
return df_total
>>> get_all_page('000100', '유한양행')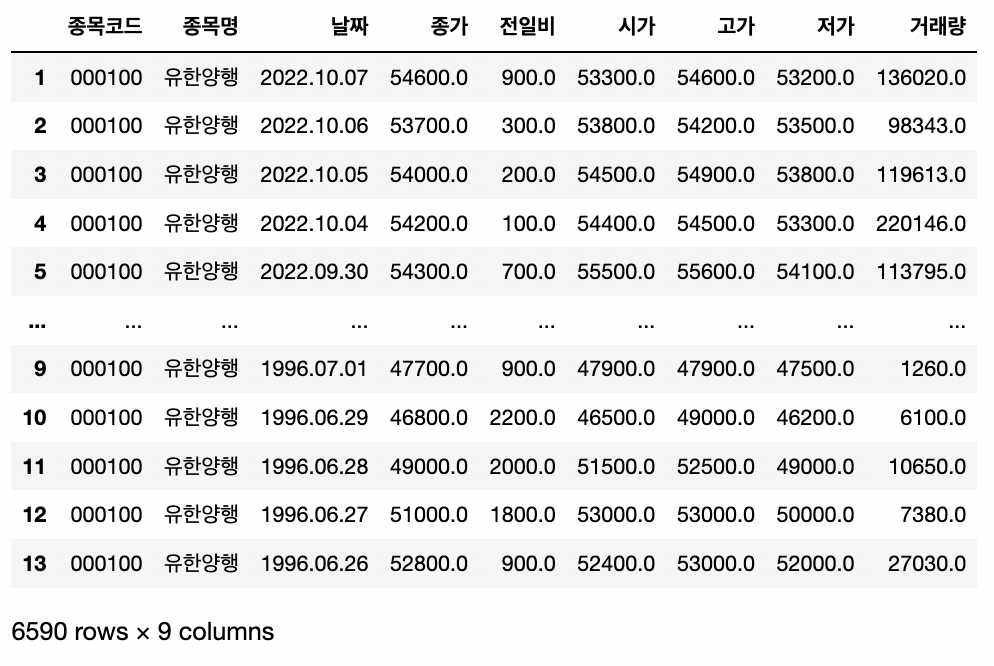
참고문헌
(1) 네이버 금융 - 유한양행 종목
https://finance.naver.com/item/sise.naver?code=000100
(2) Requests 공식문서
https://requests.readthedocs.io/en/latest/
(3) BeautifulSoup 공식문서
'멋사 AI school 7기 > TIL' 카테고리의 다른 글
| 서울특별시 다산콜센터(☎120)의 주요 민원 수집하기 - Pandas/Requests/BeautifulSoup/tqdm (1) | 2022.10.11 |
|---|---|
| FinanceDataReader 란 ? - 한국 주식 정보 가져오기 (0) | 2022.10.09 |
| 씨본(Seaborn) 시각화 도구 이해하기 (2) (0) | 2022.10.09 |
| 씨본(Seaborn) 시각화 도구 이해하기 (1) (0) | 2022.10.08 |
| 판다스(Pandas) 이해하기 - Series, DataFrame (0) | 2022.10.08 |
'멋사 AI school 7기/TIL' Related Articles
more


Comments