
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 네이버금융
- 해커랭크
- Beautifulsoup
- dataframe
- 깊은복사
- numpy
- 비밀지도
- Python
- hackerrank
- 수치형변수
- googlefont
- 프로그래머스
- Github
- 한국주식
- GIT
- FinanceDataReader
- 영어한글폰트차이
- 구글폰트
- 숫자형
- 깃허브블로그
- 데이터수집
- 서울정보소통광장
- PANDAS
- 120주요질문
- 카카오채용코테'
- Repositories
- Requests
- seaborn
- github blog
- SettingWithCopyWarning
Archives
- Today
- Total
데린이 재영
씨본(Seaborn) 시각화 도구 이해하기 (1) 본문
목표 설정
- 멋쟁이사자 AI 스쿨 6일차(220926) 학습 내용 정리하기
- Seaborn 에서 제공하는 시각화 도구 개념 정리
배운 내용 정리
- 라이브러리, 데이터 로드
import pandas as pd
import numpy as np
import seaborn as sns
# seaborn 에서 제공하는 앤스컴콰르텟 데이터셋 로드 방법
df = sns.load_dataset("anscombe")- 버전 확인, 최신 버전으로 업그레이드 하는 방법
# 버전 확인
pd.__version__
# 최신 버전으로 업그레이드
!pip install seaborn --upgrade- 컬러맵 확인 : plt.colormap()
- 기술 통계값 확인
- 수치형 변수에 대한 기술통계값 : df.describe()
- 범주형 변수에 대한 기술통계값 : df.describe(include="object")
- 수치형 변수 컬럼을 범주 기술통계값 보는 방법 : df["컬럼명"].astype(str).describe()
- 수치형 변수 컬럼 2개 이상, 범주 기술통계값 보는 방법 : df[["컬럼1", "컬럼2"]].astype(str).describe()
- 결측치 보기
- True, False 값으로 결측치 유무 확인 : df.isnull()
- 결측치 개수 확인 : df.isnull.sum()
- 결측치 비율 확인 : df.isnull.mean()
- 수치형 vs 범주형 변수 확인방법
- 유니크값을 통해 수치형인지 범주형인지 확인 (유니크값이 많으면 수치형, 적으면 범주형에 가깝다고 볼 수 있음)
- 전체 수치 변수에 대해 히스토그램 그리기 : df.hist() ▶ 판다스에 내장된 기능
- bins 값을 크게 하면 도수 분포표로 볼 수 있음 (중간중간 이 빠진 모양 그래프는 범주형 변수에 가깝다고 볼 수 있음)
- 수치형 변수만 가져오는 방법
- df_num = df.select_dtypes(include="number")
- 비대칭도(왜도)
- skew 출력 : df.skew()
- skew 값 정렬 : df.skew().sort_values()
- 첨도
- kurt 출력 : df.kurt()
- 0일 때가 normal 임을 알 수 있으며 피셔의 정의를 사용 함 ▶ 0에 가까울수록 정규분포에 가까움
- 정규화
- (관측치 - 평균) / 표준편차
- 상관분석
- 두 변수간의 연관 정도를 나타낼 뿐, 인과관계를 설명하는 것은 아님
- 데이터 프레임 전체의 수치변수에 대해 상관계수 구하기 : df.corr()
- 옵션을 따로 정의하지 않으면 피어슨 상관계수로 정의
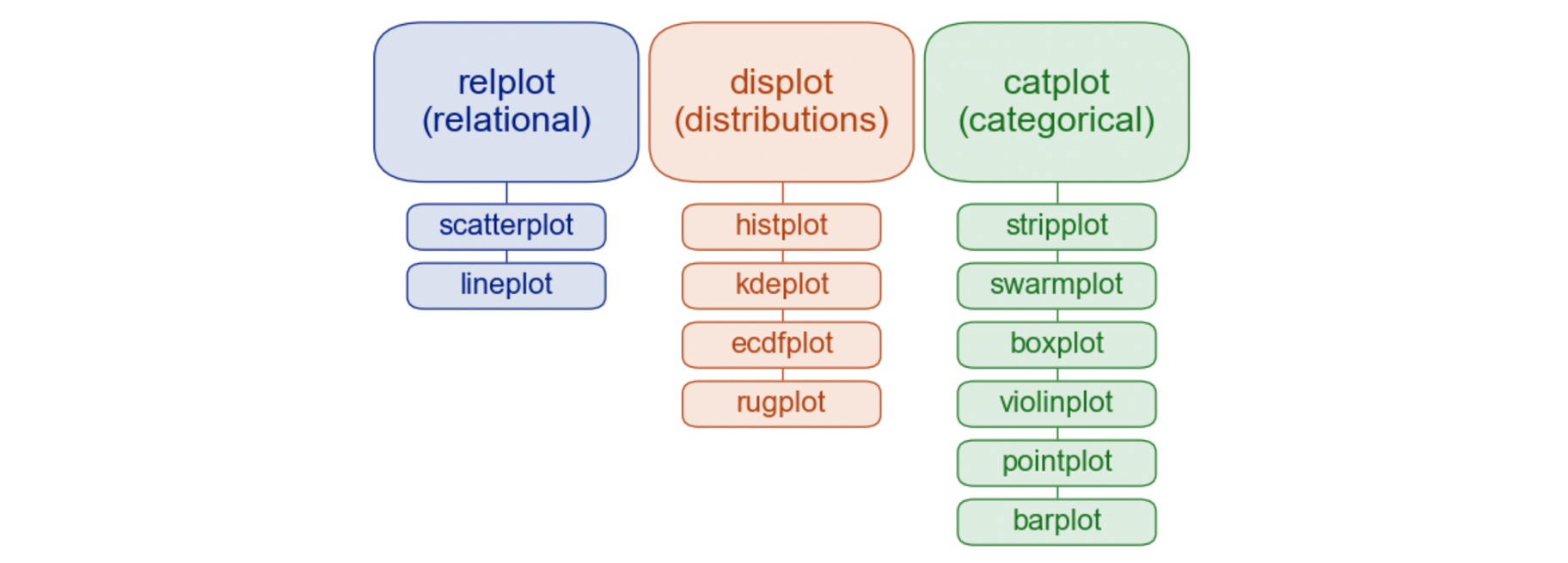
- 1개의 수치변수에 대해 시각화 하기
- sns.displot(data=df, x="컬럼명1", kde=True, hue="컬럼명2", col="컬럼명3")
- x축에 대한 y축(count값) 히스토그램
- hue : 범주형 데이터를 색별로 나눔 (Group by 기능)
- kde : 부드러운 곡선을 나타내 줌
- col : 범주형 데이터에 따라 서브 플롯을 만들어 줌
- sns.kdeplot(data=df, x="컬럼명")
- x축에 대한 y축(density값) 곡선 그래프
- 커널 밀도 추정 (kernal density estimation) 그래프 ▶ 상대량(비율)을 시각화
- sns.rugplot(data=df, x="컬럼명")
- 작은 선분(rug)으로 데이터들의 위치 및 분포를 보여줌
- sns.boxplot(data=df, x="컬럼명")
- x축에 대한 사분위 수 표현
- 다이아몬드 기호 : 이상치
- sns.violinplot(data=df, x="컬럼명")
- kdeplot을 데칼코마니 형식으로 마주보고 그린 그래프
- sns.displot(data=df, x="컬럼명1", kde=True, hue="컬럼명2", col="컬럼명3")
- 2개 이상의 수치변수에 대해 시각화 하기
- replot과 residplot 차이
- reg의 직선이 resid의 0축으로 나타남
- regplot : 회귀선 그리기
- residplot : 회귀선과 얼마나 가깝고 먼지를 나타냄
- regplot과 lmplot 차이
- lmplot은 regplot의 서브 플롯을 그릴 수 있음
- sns.pairplot(data=df.sample(100), hue="컬럼명")
- data=df 해도 되지만, 각 변수에 대해 짝을 지어 전체 변수에 대한 상관관계를 그리기 때문에, 시간이 오래 걸림
- 임의로 데이터를 추출해서 그리는게 효율적
- 변수 쌍에 대해 대략적인 상관 관계를 알 수 있음
- ci : 신뢰구간을 의미하는 파라미터
- replot과 residplot 차이
- 상삼각 대각행렬
- 대각선을 기준으로 대칭이기 때문에, 가독성을 높이기 위해 일부 제거
- matrix를 상삼각행렬 만들기 : mask = np.triu(np.ones_like(df.corr))
- 대각선 기준으로 제거 X : sns.heatmap(df.corr(), cmap="coolwarm")
- 대각선 기준으로 제거 : sns.heatmap(df.corr(), cmap="coolwarm", annot=True, mask=mask)
참고문헌
(1) 컬러맵
https://matplotlib.org/stable/tutorials/colors/colormaps.html
(2) 비대칭도(왜도)
https://ko.wikipedia.org/wiki/%EB%B9%84%EB%8C%80%EC%B9%AD%EB%8F%84
(3) 첨도
https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8F%84
(4) 상관분석
https://ko.wikipedia.org/wiki/%EC%83%81%EA%B4%80_%EB%B6%84%EC%84%9D
(5) seaborn 공식문서
https://seaborn.pydata.org/tutorial/function_overview.html
↓ 앤스컴 콰르텟, 수치형 데이터에 대한 시각화 결과 보기 - 1편
https://velog.io/@jaeyoung_jung/Python-EDA-%EC%88%98%EC%B9%98%ED%98%95-%EB%8D%B0%EC%9D%B4%ED%84%B0-1
↓ 앤스컴 콰르텟, 수치형 데이터에 대한 시각화 결과 보기 - 2편
https://velog.io/@jaeyoung_jung/Python-EDA-%EC%88%98%EC%B9%98%ED%98%95-%EB%8D%B0%EC%9D%B4%ED%84%B0-2
'멋사 AI school 7기 > TIL' 카테고리의 다른 글
| FinanceDataReader 란 ? - 한국 주식 정보 가져오기 (0) | 2022.10.09 |
|---|---|
| 씨본(Seaborn) 시각화 도구 이해하기 (2) (0) | 2022.10.09 |
| 판다스(Pandas) 이해하기 - Series, DataFrame (0) | 2022.10.08 |
| 파이썬(Python) 제어문과 함수 이해하기 - 조건문/반복문/함수 (1) | 2022.10.08 |
| 파이썬(Python) 자료형 이해하기 - Number/String/List/Tuple/Dictionary/Set/Bool (1) | 2022.10.08 |
'멋사 AI school 7기/TIL' Related Articles
more

Comments